iDesign Inc.
WordⅡDITA
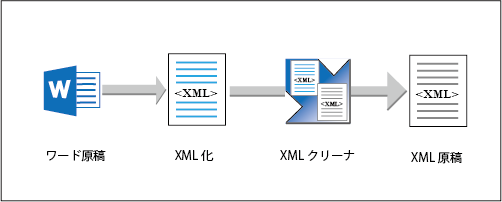
ワード原稿をDITAに変換
 XMLクリーナ
XMLクリーナ
XML化したワード原稿から不要なXMLコードを取り除くXMLクリーナです。
不要なコードを除去するXMLクリーナ
ワード原稿をXMLで保存した場合、言語指定など不要なコードが多く含まれます。これらのDITA化に不要なコードを取り除くのがXMLクリーナです。
| XML化したワード原稿 | XMLクリーナ処理後 |
|---|---|
| <H2 xml:lang="EN-US"> <Figure> <ImageData src=""/> </Figure> 1-1 WordⅡDITAの概要 </H2> <P xml:lang="EN-US"> </P> <P xml:lang="EN-US">WordⅡDITAは、ワード原稿を効率よくDITAに変換するためのツール群です。ワードからDITA CMSに単純なコピペ作業なしにDITAドキュメントを作成するために使用します。 </P> <P xml:lang="EN-US">XMLで保存したワード原稿を使い、DITAに変換します。 </P> |
<H2>1-1 WordⅡDITAの概要 </H2> <p>WordⅡDITAは、ワード原稿を効率よくDITAに変換するためのツール群です。ワードからDITA CMSに単純なコピペ作業なしにDITAドキュメントを作成するために使用します。</p> <p>XMLで保存したワード原稿を使い、DITAに変換します。</p> |
これらの不要な要素を取り除くと同時に、ギリシャ文字などの一部の特殊文字もDITAのコードに変換しておきます。一括して行える作業をこのXMLクリーナで処理します。このXMLファイルを使ってDITAに変換していきます。
XMLクリーナの機能
XMLクリーナでは以下の処理が行われます。
- 不要なコード、言語文字種指定の削除
- 特殊文字の一括変換
- テキストボックス、図タイトル、表タイトルの文字列抽出(翻訳処理用)
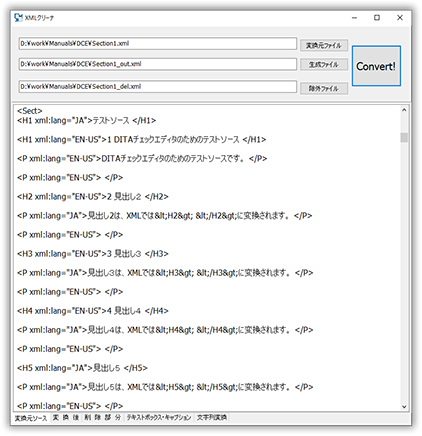
変換元ワードXML原稿
XMLに保存したワード原稿を読み込みます。
XMLクリーナ変換後のXML原稿
保存ファイルを指定して処理を行いその結果を表示、保存します。
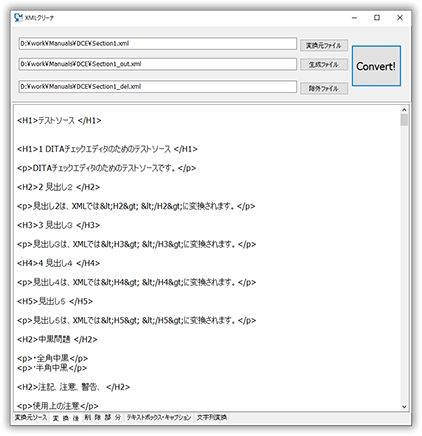
削除コード部分
確認用に、削除したコードを表示、保存します。
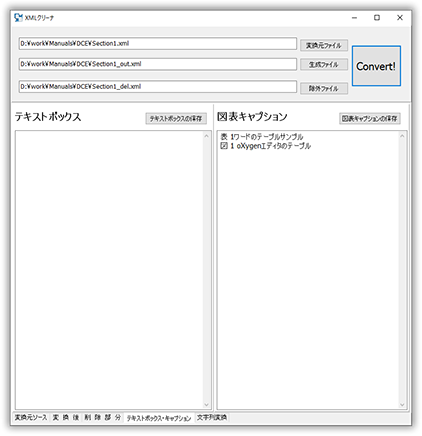
テキストボックスのテキストと図、表のキャプション
テキストボックスのテキストと図、表のキャプションの文字列を抽出し、必要であれば保存します。
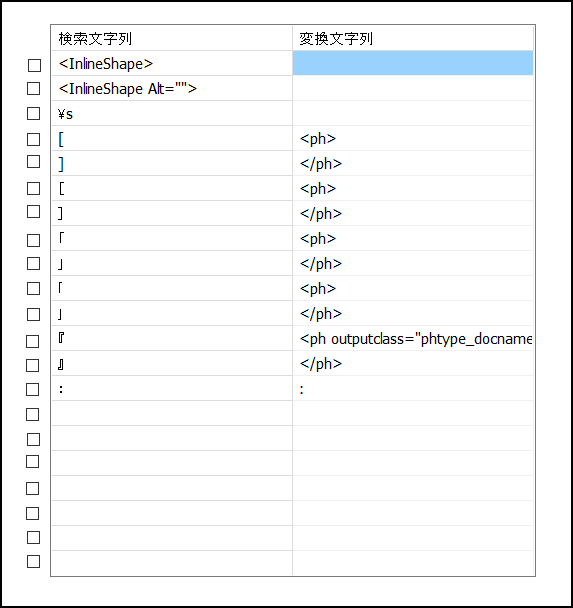
DITA用に文字の一括置換を行う
ワード原稿からDITAで使う特別な文字などを一括して変換します。
©2021- iDesign Inc.,